Reflector
This is the code base for the Reflector demo (formerly called agenda-talk-diff) for the leads : Troy Web Consulting panel (A Chat with AWS about AI: Real AI/ML AWS projects and what you should know) on 6/14 at 430PM.
The target deliverable is a local-first live transcription and visualization tool to compare a discussion's target agenda/objectives to the actual discussion live.
S3 bucket:
Everything you need for S3 is already configured in config.ini. Only edit it if you need to change it deliberately.
S3 bucket name is mentioned in config.ini. All transfers will happen between this bucket and the local computer where the script is run. You need AWS_ACCESS_KEY / AWS_SECRET_KEY to authenticate your calls to S3 (done in config.ini).
For AWS S3 Web UI,
- Login to AWS management console.
- Search for S3 in the search bar at the top.
- Navigate to list the buckets under the current account, if needed and choose your bucket [
reflector-bucket] - You should be able to see items in the bucket. You can upload/download files here directly.
For CLI, Refer to the FILE UTIL section below.
FILE UTIL MODULE:
A file_util module has been created to upload/download files with AWS S3 bucket pre-configured using config.ini. Though not needed for the workflow, if you need to upload / download file, separately on your own, apart from the pipeline workflow in the script, you can do so by :
Upload:
python3 file_util.py upload <object_name_in_S3_bucket>
Download:
python3 file_util.py download <object_name_in_S3_bucket>
If you want to access the S3 artefacts, from another machine, you can either use the python file_util with the commands mentioned above or simply use the GUI of AWS Management Console.
To setup,
- Check values in config.ini file. Specifically add your OPENAI_APIKEY if you plan to use OpenAI API requests.
- Run
export KMP_DUPLICATE_LIB_OK=Truein Terminal. [This is taken care of in code, but not reflecting, Will fix this issue later.]
NOTE: If you don't have portaudio installed already, run brew install portaudio
-
Run the script setup_depedencies.sh.
chmod +x setup_dependencies.shsh setup_dependencies.sh <ENV>
ENV refers to the intended environment for JAX. JAX is available in several variants, [CPU | GPU | Colab TPU | Google Cloud TPU]
ENV is :
cpu -> JAX CPU installation
cuda11 -> JAX CUDA 11.x version
cuda12 -> JAX CUDA 12.x version (Core Weave has CUDA 12 version, can check with nvidia-smi)
```sh setup_dependencies.sh cuda12```
- If not already done, install ffmpeg.
brew install ffmpeg
For NLTK SSL error, check here
- Run the Whisper-JAX pipeline. Currently, the repo can take a Youtube video and transcribes/summarizes it.
python3 whisjax.py "https://www.youtube.com/watch?v=ihf0S97oxuQ"
You can even run it on local file or a file in your configured S3 bucket.
python3 whisjax.py "startup.mp4"
The script will take care of a few cases like youtube file, local file, video file, audio-only file, file in S3, etc. If local file is not present, it can automatically take the file from S3.
OFFLINE WORKFLOW:
-
Specify the input source file] from a local, youtube link or upload to S3 if needed and pass it as input to the script.If the source file is in
.m4aformat, it will get converted to.mp4automatically. -
Keep the agenda header topics in a local file named
agenda-headers.txt. This needs to be present where the script is run. This version of the pipeline compares covered agenda topics using agenda headers in the following format.agenda_topic : <short description>
-
Check all the values in
config.ini. You need to predefine 2 categories for which you need to scatter plot the topic modelling visualization in the config file. This is the default visualization. But, from the dataframe artefact calleddf_<timestamp>.pkl, you can load the df and choose different topics to plot. You can filter using certain words to search for the transcriptions and you can see the top influencers and characteristic in each topic we have chosen to plot in the interactive HTML document. I have added a new jupyter notebook that gives the base template to play around with, namedViz_experiments.ipynb. -
Run the script. The script automatically transcribes, summarizes and creates a scatter plot of words & topics in the form of an interactive HTML file, a sample word cloud and uploads them to the S3 bucket
-
Additional artefacts pushed to S3:
- HTML visualization file
- pandas df in pickle format for others to collaborate and make their own visualizations
- Summary, transcript and transcript with timestamps file in text format.
The script also creates 2 types of mappings.
- Timestamp -> The top 2 matched agenda topic
- Topic -> All matched timestamps in the transcription
Other visualizations can be planned based on available artefacts or new ones can be created. Refer the
section Viz-experiments.
Visualization experiments:
This is a jupyter notebook playground with template instructions on handling the metadata and data artefacts generated from the pipeline. Follow the instructions given and tweak your own logic into it or use it as a playground to experiment libraries and visualizations on top of the metadata.
WHISPER-JAX REALTIME TRANSCRIPTION PIPELINE:
We also support a provision to perform real-time transcripton using whisper-jax pipeline. But, there are a few pre-requisites before you run it on your local machine. The instructions are for configuring on a MacOS.
We need to way to route audio from an application opened via the browser, ex. "Whereby" and audio from your local microphone input which you will be using for speaking. We use Blackhole.
-
Install Blackhole-2ch (2 ch is enough) by 1 of 2 options listed.
-
Setup Aggregate device to route web audio and local microphone input.
Be sure to mirror the settings given
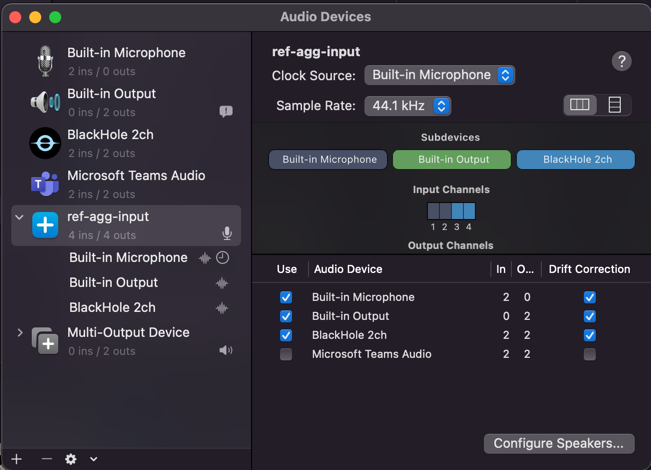
-
Setup Multi-Output device
Refer
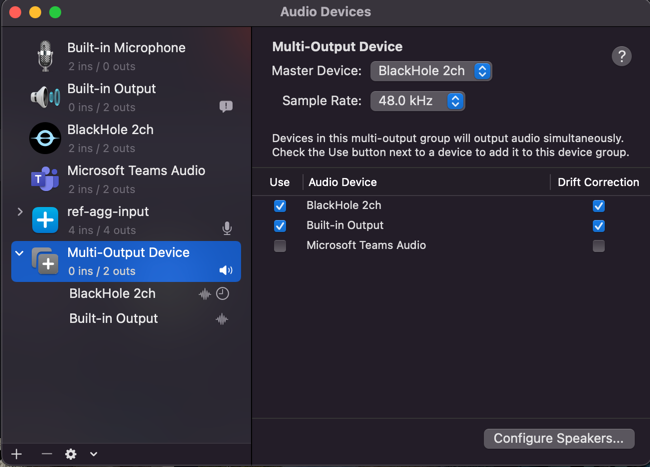
-
Set the aggregator input device name created in step 2 in config.ini as
BLACKHOLE_INPUT_AGGREGATOR_DEVICE_NAME -
Then goto
System Preferences -> Soundand choose the devices created from the Output and Input tabs. -
The input from your local microphone, the browser run meeting should be aggregated into one virtual stream to listen to and the output should be fed back to your specified output devices if everything is configured properly. Check this before trying out the trial.


Permissions:
You may have to add permission for "Terminal"/Code Editors [Pycharm/VSCode, etc.] microphone access to record audio in
System Preferences -> Privacy & Security -> Microphone,
System Preferences -> Privacy & Security -> Accessibility,
System Preferences -> Privacy & Security -> Input Monitoring.
From the reflector root folder,
run python3 whisjax_realtime.py
The transcription text should be written to real_time_transcription_<timestamp>.txt.
NEXT STEPS:
- Create a RunPod setup for this feature (mentioned in 1 & 2) and test it end-to-end
- Perform Speaker Diarization using Whisper-JAX
- Based on the feasibility of the above points, explore suitable visualizations for transcription & summarization.